ollvm相关逆向题目的解决方法

ollvm相关逆向题目的解决方法
对于我们常见的ollvm混淆无非就三种,一种是控制流平坦化,一种是指令替换,一种是虚假控制流。针对这三种混淆,我们可以分别利用不同的方式来进行清除,在一定程度上有利于我们的分析,毕竟那那些让让望而生却的代码,感觉有点头大,就着我们所遇见的题目,进行简单的归纳一下我们对于其的解决方式。
控制流平坦化
控制流平坦化的大致逻辑就是将我们的代码分割为许多的块,通过一个分发器将我们的代码各个块联系起来,结构就类似while() switch case的结构。
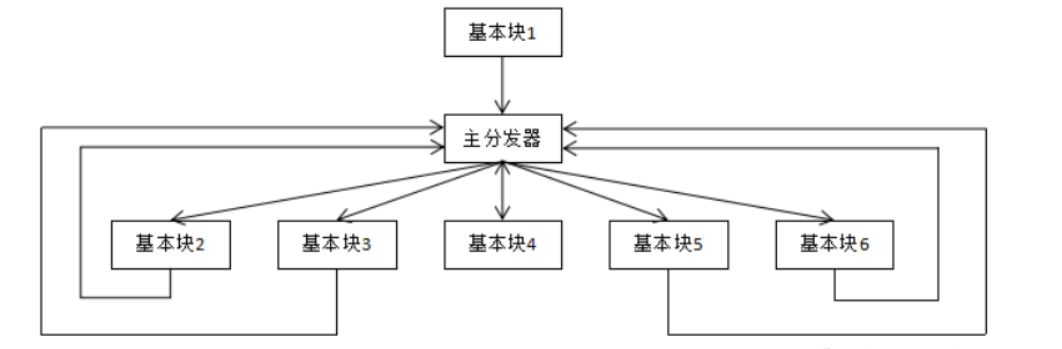
控制流平坦化,这个看过都知道,不去混淆根本就看不了
去除混淆我们有一个大佬写的一个脚本,感觉还是非常有用的
一个简单的版本
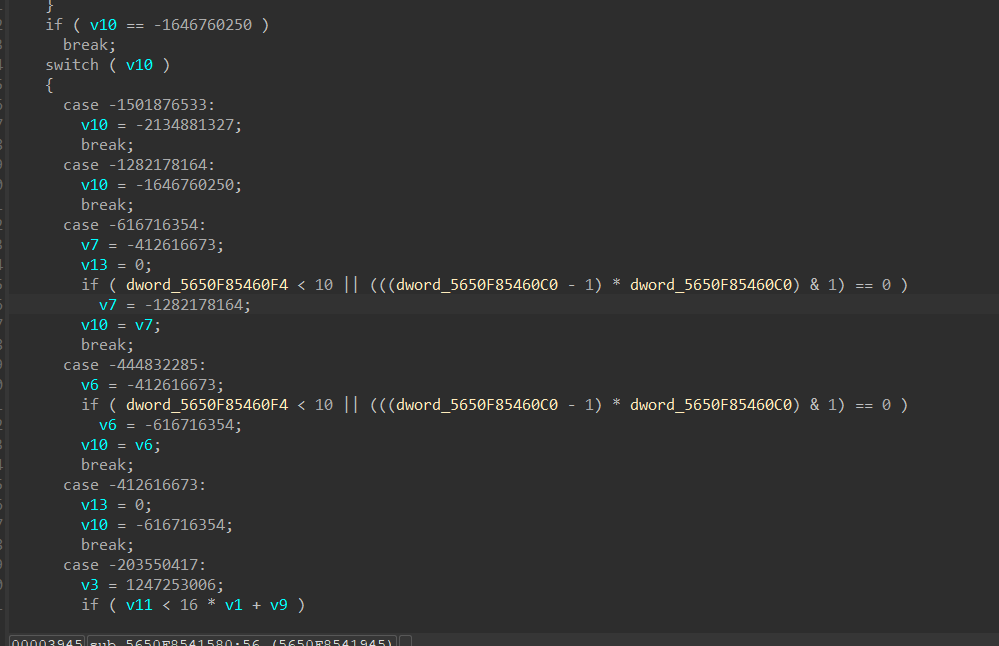
一个困难版本
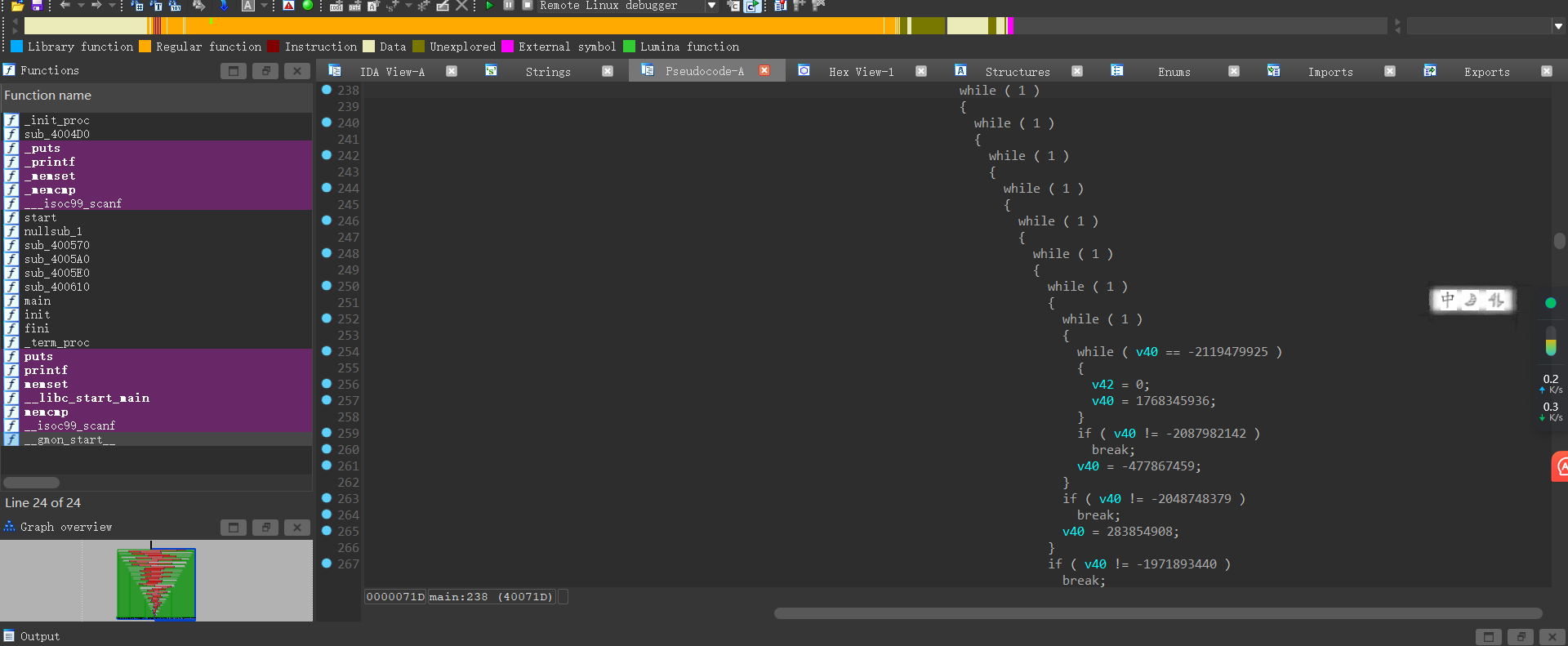

脚本的具体使用:
1 | python3 deflat.py attachment 0x005290 #python版本+脚本名+文件名+平坦化(main)起始地址 |
去除之后感觉还是非常清晰的
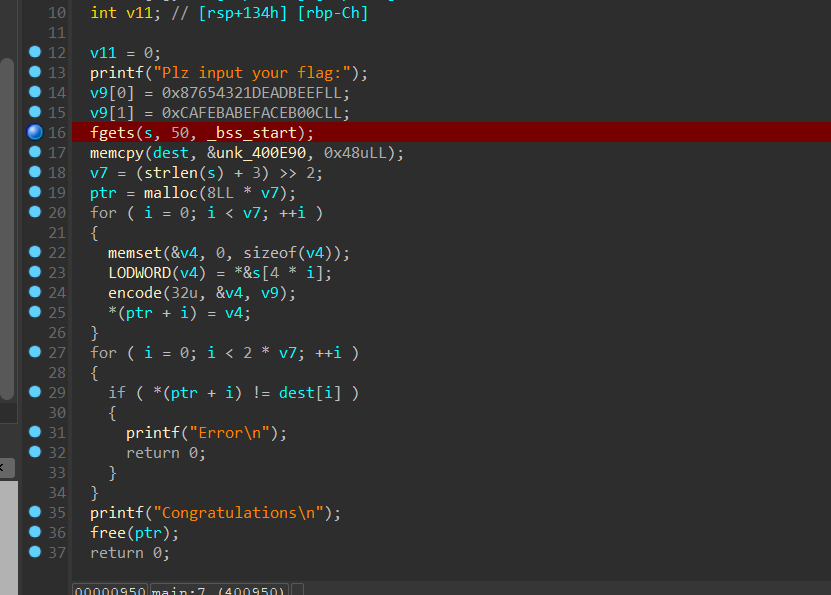
虚假控制流
对于虚假控制流,我们简单了解一下其原理。虚假控制流混淆通过加入含不透明谓词的条件跳转和永远不可以到达的基本块,来干扰IDA的控制流分析和反汇编。
下面有一个大佬对不透明谓词的解释。
(65 封私信 / 22 条消息) 利用不透明谓词混淆代码的原理是什么? - 知乎 (zhihu.com)
举一个简单的例子:
1 | if(1) |
这个if下,在永真条件下,打印我们的2222是永远到达不了的,在逻辑上我们很好理解,但是会干扰我们的IDA控制分析,而且在一大串的混淆之下,不去除的话会让我们花很多时间在分析上。
就看一个实际例子[RoarCTF 2019]polyre
前面有个控制流平坦化去除平坦化之后我们可以发现,这题下面有很多永真但是没有执行的代码,但是因为它多,而且ida分析出来很混乱,会造成我分析起来很困难。
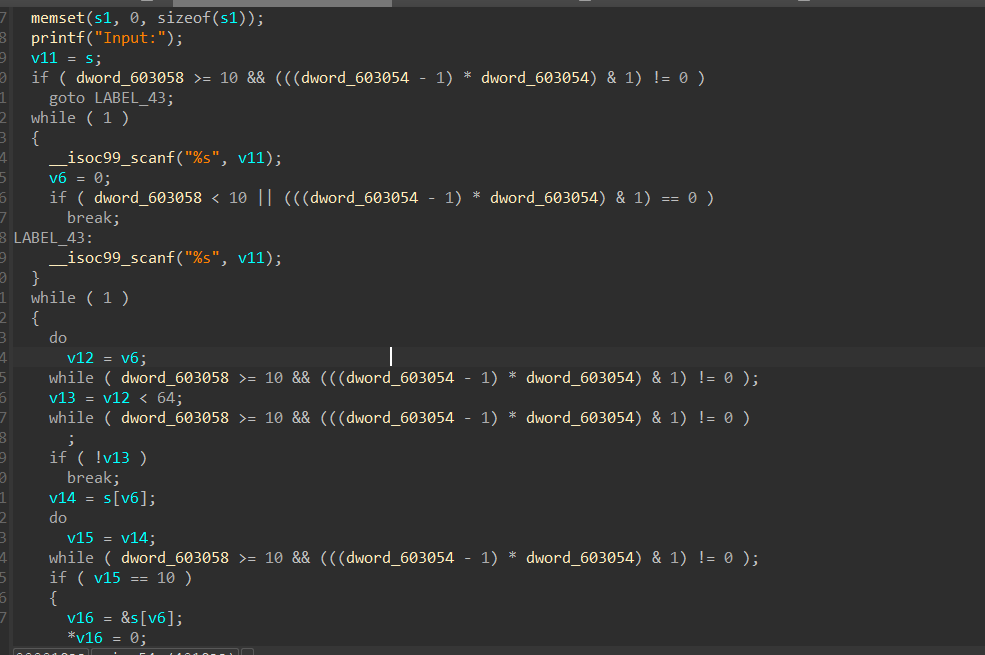
理解虚假控制流的原理,其实我们思考起来,想要去除它很简单。它不是有永真条件嘛,也就是说当我们运行一遍程序之后,走的路径全是需要执行的,因此只要我标记一下没有走的地方,将其全部nop掉即可。我们会想到一种方式就是通过我们的angr来模拟执行一下代码,然后将不执行的代码全部nop掉。
一个大佬写的关于此的研究文章,非常不错。
[原创]利用angr符号执行去除虚假控制流-软件逆向-看雪-安全社区|安全招聘|kanxue.com
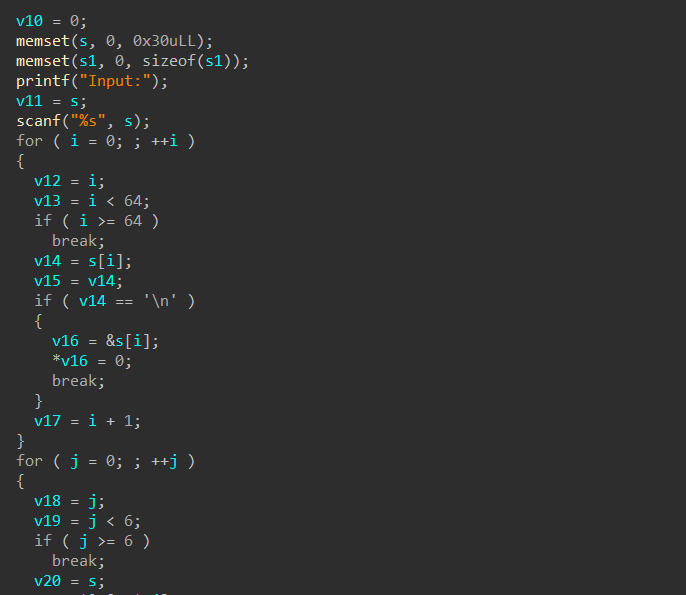
另一种就是直接从源头处理将不透明谓词改为0,这样我们ida也就能进行处理了
1 | import idaapi |
我们看一下处理之后的代码,可以发现还是很清爽的。
指令替换
所谓指令替换,就是将我们的原来的计算指令,从一个简单易懂的,变成难以理解的,但是等效的代码指令。
举一个简单的例子
1 | 2 = 1+1 |
这样就会加大我们的分析难度,下面有一个推荐的博客,介绍了一下常见的指令替换
ollvm源码分析之指令替换(1)_ollvm 花指令-CSDN博客
以2023楚慧杯 babyre这道题为例子,我们去除了前面的控制流平坦化之后,我们进入我们的加密函数,可以发现一大串难以识别具体加密的混淆,可能通过逆向经验能猜出这个加密,但是如果遇到我们不熟悉的加密就有点困难了。

对于我们的指令替换的处理,有个大佬写一个ida的插件,关于去除指令替换的插件
d801插件(网上能下的):
只需要将这个解压之后的文件,复制到我们的ida插件文件夹里面就行。
具体使用方法就是
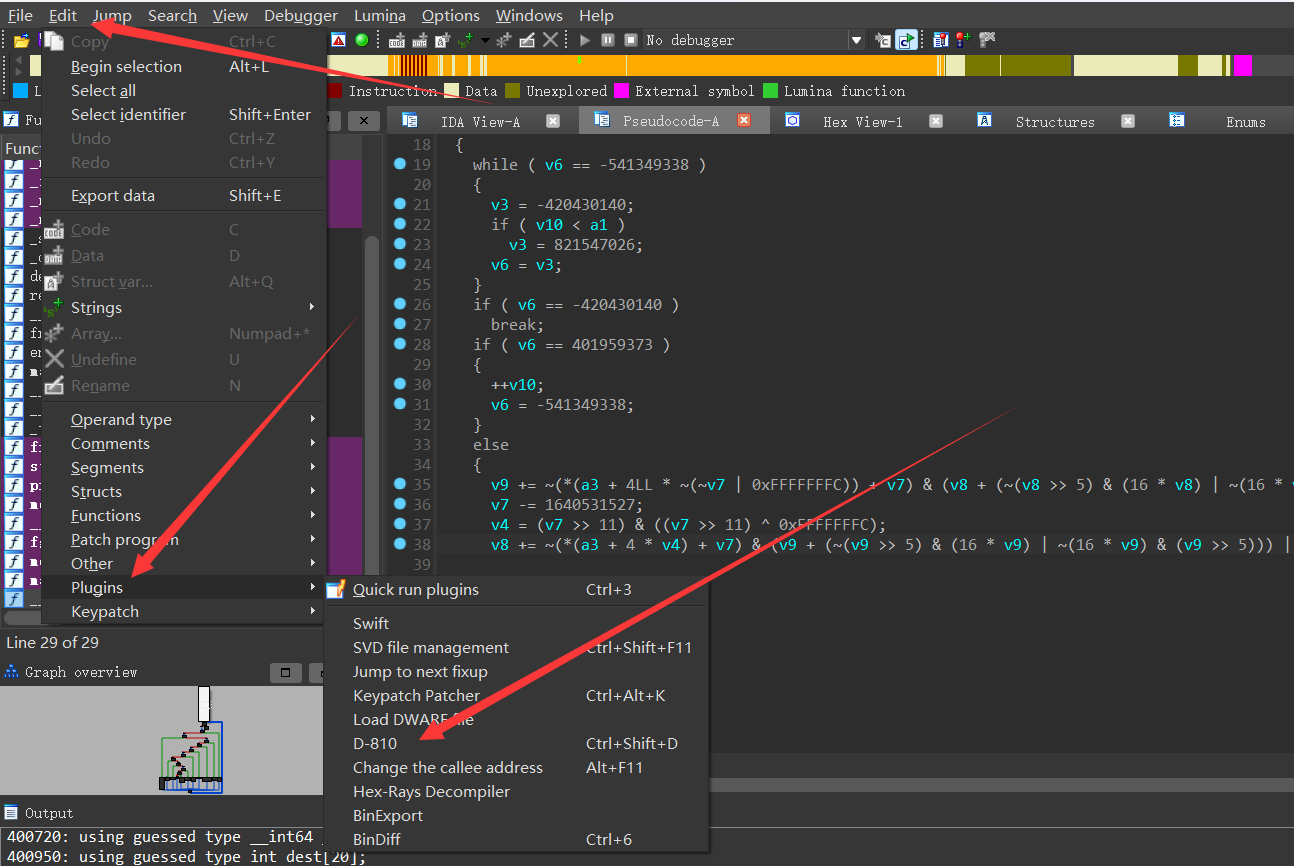
接着它会自动识别,我们只需要点击star即可
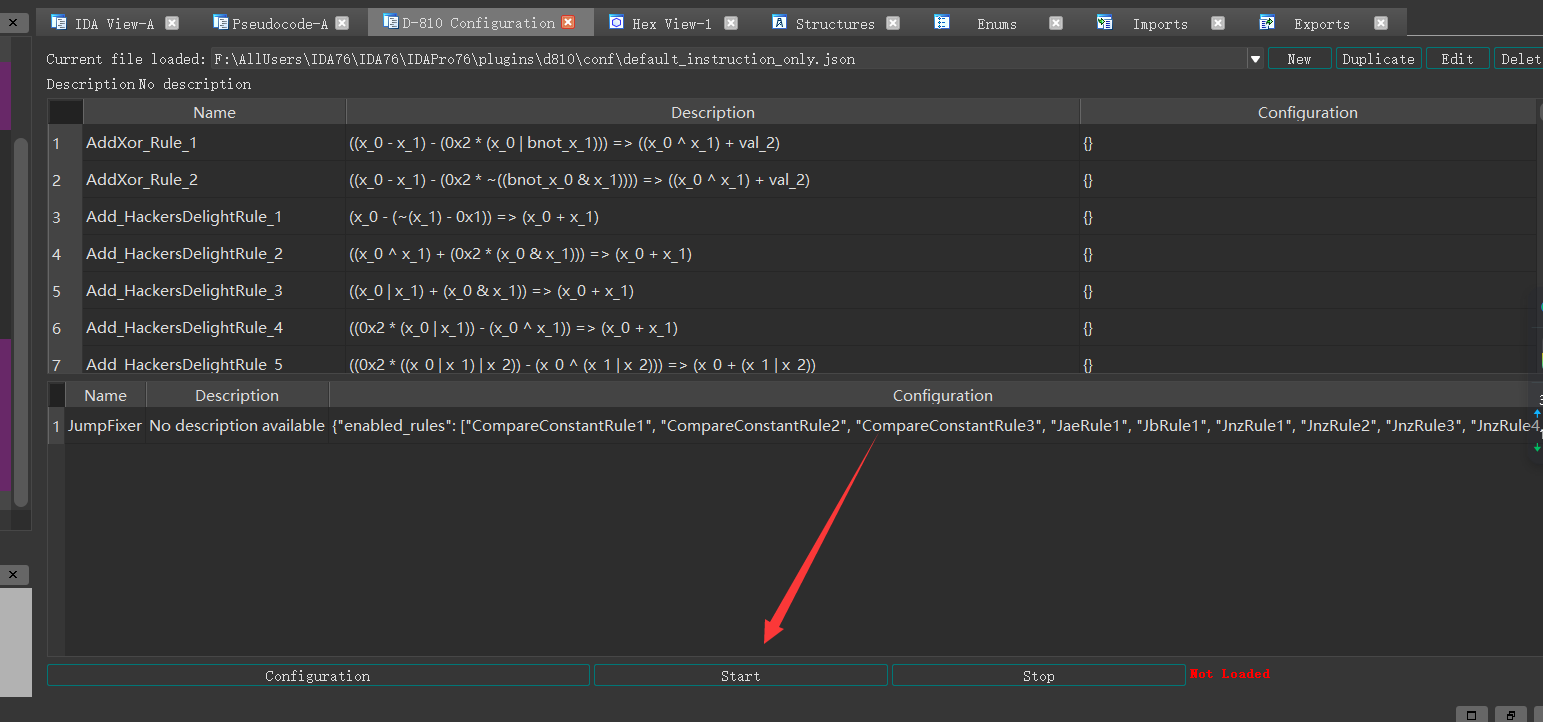
然后针对伪代码,我们按f5重新分析即可
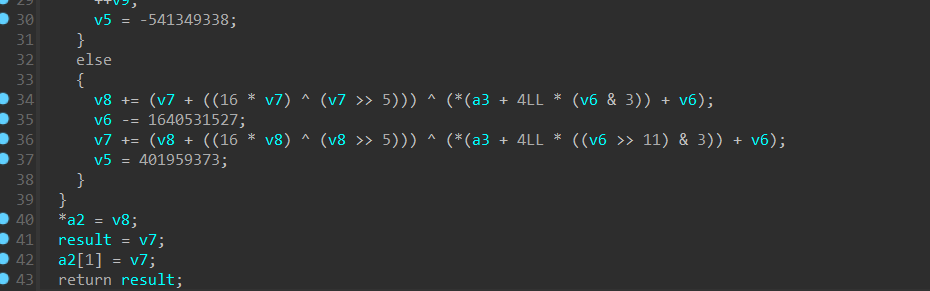
解完我们的指令替换,看起来舒服多了。
上面是针对一下比较标准的ollvm混淆,如果题目作者研究过ollvm混淆,针对原版混淆的解密可能就会失效了。对于做题倒是够用了,如果真的魔改了,到那个时候再学学,或者直接关闭ida吧.